NHibernate3 XML Mapping[Cookbook翻译]
下面为内容翻译:
使用XML映射一个类
在任何新开始的NHibernate应用程序中,建议第一步要做的是映射模型(实体类)。在这第一个示例中,我将给你演示怎么样去映射一个简单的产品类。
准备工作
在开始进行映射之前,让我们首先对Visual Studio解决方案进行一下设置。根据下面的步骤使用NHibernate发布包(程序集及相关文件)和模式(.xsd文件,用于xml的智能提示和校验)设置好你的解决方案。
1.从http://sourceforge. net/projects/nhibernate/files/ 地址下载NHibernate 3.0二进制发布包,下载后的文件名称应该是NHibernate- 3.0.0.GA-bin.zip,也许版本号会有略微不同。
2.在Visual Studio环境中,创建一个类库项目,并命名为Eg.Core,解决方案命名为Cookbook,并选中创建解决方案文件夹选项, (Cookbook是书名,书中的示例代码都会放置在此文件夹下面)。
3.删除Class1.cs文件
4.在解决方案浏览器中,右击解决方案名称Cookbook,选择在Windows资源管理器中打开文件夹。这样就在一个Windows资源管理器窗口中打开了Cookbook目录了。
5.在Cookbook文件夹中,创建一个子文件夹,命名为Lib(用于存放公共的dll,xsd等文件)
6.将刚才下载的压缩包解压,并且把Required_Bin文件夹中的所有文件和Required_For_LazyLoading\Castle文件夹中的所有文件全部拷贝到Lib目录中
7.回到Visual Studio窗口,右键单击解决方案,并且选择添加(新增),新建解决方案文件夹
8. 把上一步新建的文件夹命名为Schema
9. 右键单击刚才的Schema文件夹,并选择新增|已经存在的文件
10.在弹出的选择文件窗口中浏览到Lib文件夹,然后把nhibernate-configuration.xsd和nhibernate-mapping.xsd两个文件加进去。
11. 此时,你的解决方案浏览器中看起来如下:
现在,让我们开始跟着下面的步骤创建我们的产品(Product)类:
1. 在Eg.Core项目中,创建一个新的c#类,命名为Entity,代码如下:
namespace Eg.Core
{
public abstract class Entity
{
public virtual Guid Id { get; protected set; }
}
}
2. 新建一个类,命名为Product,代码如下:(注意virtual关键字,NHibernate在某些情况下需要创建代理类,比如延迟加载,所以这里需要加上virtual关键字,而且类不能是
sealed的)
namespace Eg.Core
{
public class Product : Entity
{
public virtual string Name { get; set; }
public virtual string Description { get; set; }
public virtual decimal UnitPrice { get; set; }
}
}
3. 生成你的解决方案,如果编译有错请改正。
接下来,为我们刚才的产品类创建一个NHibernate映射,步骤如下:
1.在解决方案浏览器中,右键单击你的项目名称,并且选择新增|新文件
2.在左侧的版面中选择数据类别。
3. 在右侧的面板中选择XML文件。
4.命名刚才的XML文件为Product.hbm.xml
5.在解决方案浏览器中,右键单击刚才新建的Product.hbm.xml文件,选择属性
6. 将生成操作从内容更改为嵌入式资源。
(注:1-6步其实就是新建一个xml文件,并设置为嵌入式资源)
7. 在编辑器中,为Product.hbm.xml文件输入下面的内容。让智能提示引导你输入(如果无智能提示,可能是你没有正确设置.xsd文件)
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2"
assembly="Eg.Core"
namespace="Eg.Core">
<class name="Product">
<id name="Id">
<generator class="guid.comb" />
</id>
<property name="Name" not-null="true" />
<property name="Description" />
<property name="UnitPrice" not-null="true"
type="Currency" />
</class>
</hibernate-mapping>
它是怎么工作的….
让我们来近距离认识一下这个Id属性,在每个产品类的实例中,这个Id属性将会包含来自数据库的主键值(这个示例中对应的类型为GUID),在NHibernate中,这个被称作POID(持久化对象唯一标识),即持久化对象标识。正如在数据库表中,每一行都有一个唯一的主键值一样,这个POID也使得在内存中的每一个实体都有一个唯一的标识来区分。
如果你是初次接触NHibernate,那么下面的setter访问器被设置成protected对你来说似乎看起来比较奇怪
这是一种简单的方法用来限制对Id属性的访问(这里是对写的访问的限制)。在产品类本身的代码外部是无法改变Id属性的值的,然而,NHibernate对Id属性的赋值是通过高度优化的反射来实现的,会忽略protected的限制,这样做可以保证你的应用程序不会在不经意间改变这个值。Id是该实体的唯一标识,应该交由NHibernate来管理维护,不应该有我们自己的应该程序来赋值的,当然,这只适用于使用代理主键的情况,如果是自然主键(业务主键)则不应该这样做。
接下来,我们创建产品实体类的映射文件(之前的Product.hbm.xml就是),当我们手工输入内容的时候,Visual Studio使用nhibernate-mapping.xsd来支持智能提示,作为一个通用的命名约定,所有的NHibernate映射文件都将以.hbm.xml结尾,并且在生成动作中必须设置为嵌入式资源。NHibernate会自动搜索你的程序集中的嵌入式资源,并且加载每一个以.hbm.xml结尾的文件。换句话会说,如果你的映射文件不以.hbm.xml结尾,那么NHibernate不会认为是映射文件而去自动加载,你自己的普通的XML文件请不要以.hbm.xml结尾。
一个经常犯的错误就是忘记把映射文件在生成动作中配置成嵌入式资源了,这样的话会报一个No Persister for class的MappingException类型的异常消息。
让我们来仔细分析一下刚才的XML映射文件,每一个XML映射文档都会包含一个hibernate-mapping元素节点,而且只能包含一个。它的xmlns属性设置了XML的命名空间,命名空间和我们的Schema文件夹中的xsd文件是一致的,如果你自己更改了xmlns属性的值,那么将无法进行智能提示和验证了。Visual Studio使用这个xmlns属性来启用智能提示和验证。
assembly属性用来告诉NHibernate,在我们的这个映射文件中,哪个默认的程序集包含有我们的类型定义,即模型实体类定义,类似地,namespace属性设置了默认的.net命名空间。通过这两个属性的设置以后,就允许我们使用简单的类名Product来代替使用程序集的完全限定名称Eg.Core.Product, Eg.Core。这里有点像我们.cs文件中的using一样。在hibernate-mapping元素节点内,我们还需要一个class元素节点,其中的name属性告诉NHibernate这个class元素节点定义的是我们的产品实体类的映射,一个class元素节点对应我们的一个实体类定义。
在class元素节点下的Id元素定义了POID,name属性对应到产品类的Id属性,和我们在C#语言中一样,这里是大小写敏感的。
generator元素节点告诉NHibernate怎么生成POID,在我们的示例中,我们告诉NHibernate使用guid.comb算法来生成,还有更多的生成POID的算法在后面会详细讲解。
property元素节点对应于我们产品类的其他属性,每一个name属性匹配我们产品类中的属性的名字。在默认情况下,NHibernate允许空值,如果你不允许值为空,请加上not-null="true"告诉NHibernate,该属性值不允许为空。
避免多余的映射选项
通常来说,最好的做法是保持你的映射文件尽可能的简短明了。NHibernate会自动扫描你的类,并且结合你的映射文件中的信息进行智能推断。在大多数情况下,在映射文件中指定你的属性的类型信息是多余的,比如产品类中的名称属性<property name="Name" not-null="true" />,如果你配置成<property name="Name" not-null="true" type="string" />是不必要的,type属性不需要告诉NHibernate,NHibernate会自动扫描你的产品类,通过反射获取Name属性的类型。默认的表名会通过类名来进行推断,例如<class name="Product" table="Product">中的table属性是不需要的,默认情况下会从name属性中获取。表的字段的名字默认情况下也会依据属性的名字推知。再次显式指定这些信息是完全不必要的。类似地,NHibernate定义的属性的一些默认值你也应该避免显式指定,例如,上面提到的not-null="true",它的默认值是false,所以你不需要去指定not-null="false",只有当和默认值不同时才需要指定,如果刻意去指定这些多余的默认值,只会使得你的映射文件难以阅读。
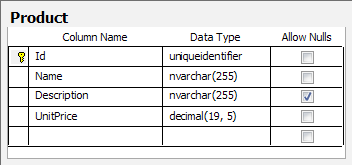
根据这个映射文件,使用Microsoft SQL Server数据库来存储产品实体的数据的表看起来应该如下图所示,如果是其它数据库则略有不同。
更多内容
我们使用NHibernate开发应用程序大致有三种方法。
*领域模型驱动方法,本书就是采用这种方法的,我们先创建模型,再映射模型,配置NHibernate,最后通过模型类和映射文件生成我们的数据库表。即模型需要手工建立,然后可以通过模型自动生成映射文件()需要做一些修改,然后通过模型和映射文件自动生成数据库表。
*先创建配置映射文件的方法看上去只有略微不同,我们首先创建映射文件,然后再创建对应的类,这是模型驱动(第一种方法)的一个迭代方法,最后通过模型类和映射文件生成数据库表。即映射文件需要手工建立,模型类通过映射文件自动生成,数据库表通过模型类和映射文件自动生成。
*首先从数据库入手的方法仅仅被推荐用于遗留的系统,由于需要依赖于原有数据库的设计,这种方法经常需要使用到映射的高级技术,很多NHibernate初学者由于经验不足,使用这种方法会碰到很多问题。
这些映射将会发生什么情况呢?
当他们被NHibernate加载的时候,NHibernate将会反序列化我们的映射文件,然后生成NHibernate映射对象图,NHibernate结合映射文件中的元数据以及我们实体类的相关信息(包括前面说的反射推知的信息)创建映射元数据。这个映射元数据包括了NHibernate对于我们的模型类必须知道的任何信息,这些信息来自于映射文件以及模型类定义。
一个自然主键是一个唯一标识,它带有语义或者业务含义,这就意味着在真实世界中对我们有一定的意义。一个代理主键是一个系统产生的唯一标识,它没有任何业务含义,在数据库表中,它的值是唯一的,用来区分不同的记录,自然(业务)主键例如以用户名,身份证号码等作为主键,代理主键例如用自动增长或者GUID等,NHibernate强烈建议使用代理主键,有两个原因如下:
第一,使用自然主键将不可避免的产生复合主键的情况。复合主键需要有多个字段来组成,这些业务键的字段可能来自其他对象。让我们来分析一下大学课程安排的模型,你的学期实体的自然键可能是Fall 2010(此为两个键组成的复合键),生物系的自然键可能是BIOL(这里是单键),生物系的一门课程的自然键可能是BIOL 101(此为两个键组成的复合键),系的自然键以及课程编号它们都存放在不同的表中,需要通过外键引用。一个系的某个学期的课程的自然键需要由学期,课程以及系三个因素来共同组成。随着层级的增加,这个自然键的字段数目会成倍的增长,而且很快将会变的非常的复杂。
第二,因为自然键有着真实世界的实际业务逻辑,它们必须随着业务逻辑而允许被更新。我们假定有一个账号的类,并且有一个UserName的属性,就算这个属性是唯一性的,但是把它作为主键也不是一个好的选择,假如UserName的一部分是由姓氏的第一个字母组成的,当有人改变了他们的名字之后,你将不得不在数据库中更新很多外键关联,如果你是用一个不带有任何业务含义的整形类型的字段作为主键的话,你现在仅仅需要更新UserName字段就可以了,不需要修改其他表中的外键关联字段。
然而,UserName仍然是一个自然键的很好的候选键,无论是单个属性的自然键或者是复合属性的自然键,它们都必须是唯一的,并且是不能为空值。从本质上说,如果在数据库中它并不是主键,但是它仍然可以是一个实体的自然键,映射一个自然键的代码如下:
<property name="UserName" not-null="true" />
</natural-id>
natural-id元素节点带有一个mutable属性,它的默认值是false,意味着它内部包含的属性或者属性集是不可改变的,或者说是常量。在这个示例中,我们将会允许我们的应用程序随时去改变一个账号的UserName的属性,所以我们设置mutable属性为true,除了对缓存有细微的改善外,这个自然键我们在数据库中会给它新建一个唯一性索引。这里的意思是,如果建了唯一性索引,则在新增或者更新的时候对数据库性能有一定的影响,但是这个影响是比较细微的。
选择ID生成器
NHibernate提供了多种可选的生成POIDs的方法,其中有些是较好的方法,推荐使用,一般地可以分为以下4中类型:
●assigned生成器需要应用程序在对象持久化之前自己给唯一标识赋值,典型的应用是使用自然键时的情况。
●Non-insert POID generators,非即时插入的主键生成器,它对于一个新的应用程序来说是最佳选择。这些生成器允许NHibernate在为一个持久化对象的唯一标识赋值之后无需立即把该持久化写回数据库,允许NHibernate在直到事务提交的时候再写回数据库,减少了事务对数据库加锁的时间占用。以下的POID生成器都属于此类型:
(仅翻译常用的几种)
▶guid使用System.Guid.NewGuid()生成一个GUID值,基于此生成器生成的所有GUID值对于一个共享数据库来说都是安全的,因为GUID不会重复。
▶increment也是一个简单的自动增长的整形类型的生成器,它的值在程序启动的时候从数据库中将主键的最大值取出来进行初始化,它不适合共享数据库的场合。如果通过NHibernate有新增记录,则NHibernate会自动加1,只能通过NHibernate进行操作数据库,所以具有排他性访问。注意,这个和数据库的自动增长是不同的。
▶foreign外键生成器,它拷贝一对一关系中的另一个对象的主键值。例如,你有联系人和顾客的一对一关联关系,外键生成器会根据联系人的ID生成一个一样的ID给顾客对象。这里其实就是共用主键的意思,比如联系人有条记录主键为1,则对应的顾客表的记录的主键值也是1,因为是一对一关系,所以这里就没问题,不适合一对多等其他情况。
●Post-insert POID generators即时插入的POID生成器需要数据立即持久化来取得它的ID,这种方式为微妙的改变NHibernate的行为,并且在性能上会有一定的影响。正因为如此,使用这种方法是强烈不建议的。这种方式是基于数据库的主键生成策略,如果不进行即时插入,那么NHibernate就无法获知当前的主键值,比如MS SQL的自动增长标识。
▶identity返回一个数据库生成的ID。
▶根据数据库的触发器生成一个ID。
●最后一种方法是native生成器,这种生成器会依赖于不同的数据库有NHibernate决定使用哪个具体的生成器。当使用Microsoft SQL Server, DB2, Informix, MySQL, PostgreSQL, SQLite, and Sybase数据库时,NHibernate选择了identity生成器,当使用Oracle and Firebird数据库时,NHibernate选择了sequence生成器,在Ingres中则是hilo。
NHibernate3 XML Mapping[Cookbook翻译]翻译到此结束。
 "
"2011/9/8 18:13:10 | Nhibernate3教程 | |